
Shortcutting a standard library

Coauthored by Julian Ceipek
We recently decided to significantly expand Dark’s standard library. While our standard library has a lot of functionality for the Dark “framework”, including HTTP, worker/queue, and datastore functions, we were a little short on normal functions you’d expect from a “batteries included” language, such as functions for math and manipulating standard datatypes like lists, dictionaries, numbers, and strings.
As a shortcut to ship faster, we decided to take our lead from the Elm standard library. Elm’s standard library is well-designed, with significant thought given to usability. Dark and Elm are both intended for a similar audience: frontend developers using functional languages for the first time. The Dark and Elm languages share many commonalities, with Dark taking influence from Elm and other similar languages like OCaml. Really, Elm has the perfect standard library from which to take inspiration!
This also isn’t our first rodeo with the Elm standard library: Dark was written in Elm for its first year, and we used Elm’s standard library as an influence for our tablecloth OCaml standard library.
Given these similarities and our prior experience, expanding Dark’s standard library using Elm’s library as an influence seemed trivial. However, minor semantic differences between Elm and Dark led to significant subtleties in how this worked in practice.
Language differences
In many cases we needed to implement different behavior or function signatures from the Elm functions we were looking at. All of these boiled down to subtle language differences.
Pipeline ordering
Elm supports pipelining as a first-class language feature. For example, in Elm you can write:
[1,2,3]
|> List.take 1This is the same as:
List.take 1 [1,2,3]Most Elm functions are designed to allow easy pipelining: the main value that you’re operating on goes last. Paul has spent a significant amount of time writing Clojure, which uses pipelining but does not adhere as strongly to this principle, and it’s one of the many things that makes Elm a delight to use.
While Dark is also designed for pipelining, we pipe into the first position instead. Because we pipe into the first position, we obviously need to change the parameter order to get the same effect.
In Dark,
[1,2,3]
|> List::take 1is a shorthand for
List::take [1,2,3] 1But it goes a bit further than that. Elm’s function names often take into account the parameter order. For example, in the following cases, Elm uses the suffixes “by”, “base” and “with”, referring to the first argument.
List.map (remainderBy 4) [ -5, -4, -3, -2, -1, 0, 1, 2, 3, 4]
-- [ -1, 0, -3, -2, -1, 0, 1, 2, 3, 0]
logBase 10 100 == 2
logBase 2 256 == 8
sortWith flippedComparison [1,2,3,4,5] == [5,4,3,2,1]
flippedComparison a b =
case compare a b of
LT -> GT
EQ -> EQ
GT -> LTFor Dark’s versions we ended up going with List::sortByComparator instead of List.sortWith, and Int::remainder for remainerBy in order to match the naming to the parameter order required by the different pipeline behavior. We forgot to add a log function, but we'd probably have called it Int::log.
Namespaces
Elm puts a lot of math functions in the global namespace, including abs and pi. Having small recognizable names for math allows you to understand a complex expression more quickly and effectively than if it were written out, and so these short names can often make sense. When we weigh the design goals of Dark however, it starts to look quite different.
Autocomplete
Dark developers are learning the Dark language and the Dark editor in tandem. As such, we rely heavily on autocomplete to make the standard library discoverable. Putting all functions in module namespaces makes it easy to discover functions, so it makes sense to put these functions in either the Math namespace, or a relevant namespace like Int or Float.
Generic Classes
Elm has a number typeclass which Dark doesn't have yet, which means that in Elm, abs can work with both Ints and Floats. Putting these functions in modules allows us to distinguish based on type: we have Int::absoluteValue and Float::absoluteValue.
Function Length
Finally, we decided not to use short function names. We perceive that Dark is not typically used for complex math expressions, so there isn’t as much value in making function names short. Math expressions are much more common in frontends, for which Elm is designed.
We do have plans to support short names by providing control over how our editor displays names, or to increase function discoverability by aliasing different names in our autocomplete, but we haven’t fleshed out those ideas yet.
Safety and Usability: Pick Two
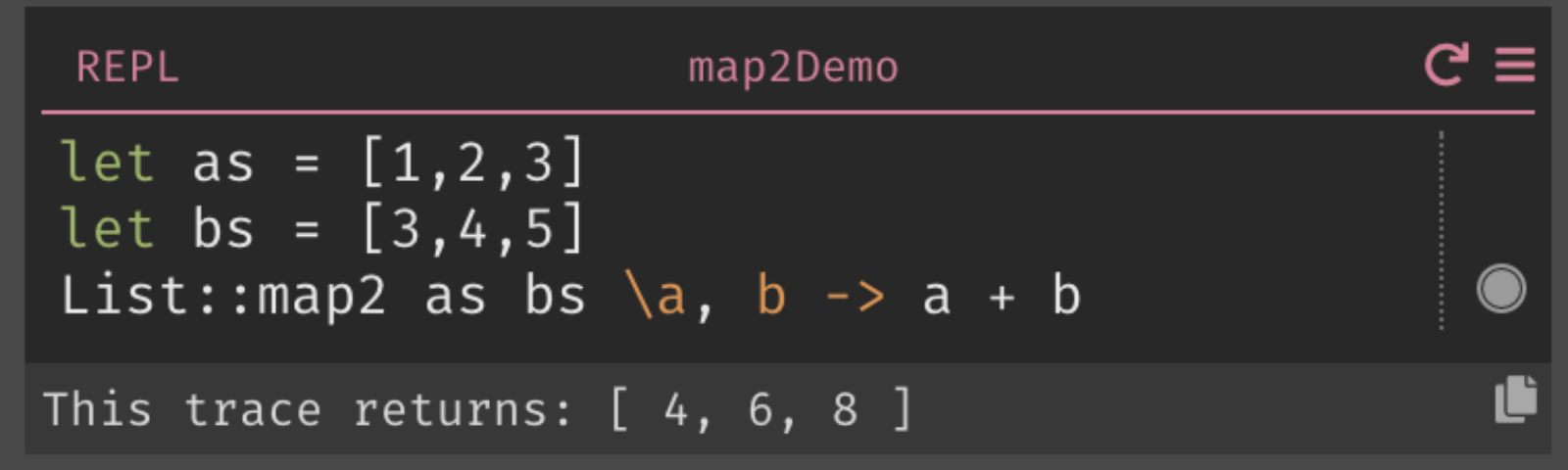
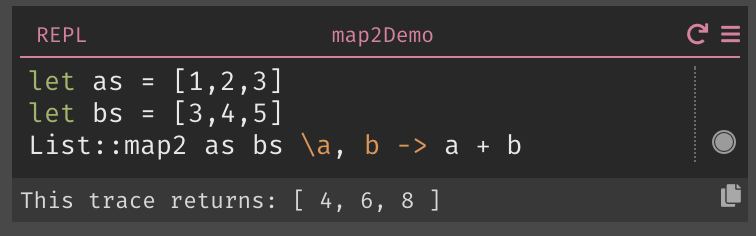
Standard libraries need to manage a fine line between safety and ease of use. Elm has to walk this line, and not all of its functions come down on the same side of it. For example, Elm’s String.uncons returns the unwieldy Maybe (Char, String). Meanwhile, List.map2 silently drops elements from the longer list when the lists have different lengths.
Dark tries to support both safety and ease-of-use where possible. We built a feature called the “Error Rail”, which automatically unwraps Options and Results to make them easier to use during the early, exploratory stages of coding, when writing something quickly and simply is more important than handling every eventuality. Later, when the coder wants to be sure that their code works in every special case, they can “take the function off the error rail” to handle edge cases.
This affects the design of Dark’s List::map2. This function takes two lists and calls a function on arguments in the same positions in both lists. When the lists are different lengths, should we:
- choose ease-of-use by making it just work (by unsafely ignoring extra elements in the longer list like Elm does)?
- or choose the safety of making sure the programmer knows when the lists are different length (at the cost of wrapping the return value in an
Optionthat the programmer has to handle, which is similar to what OCaml Core does)?
Because of the error rail, implementing List::map2 to return an Option makes the common case of the lists having equal lengths easy:
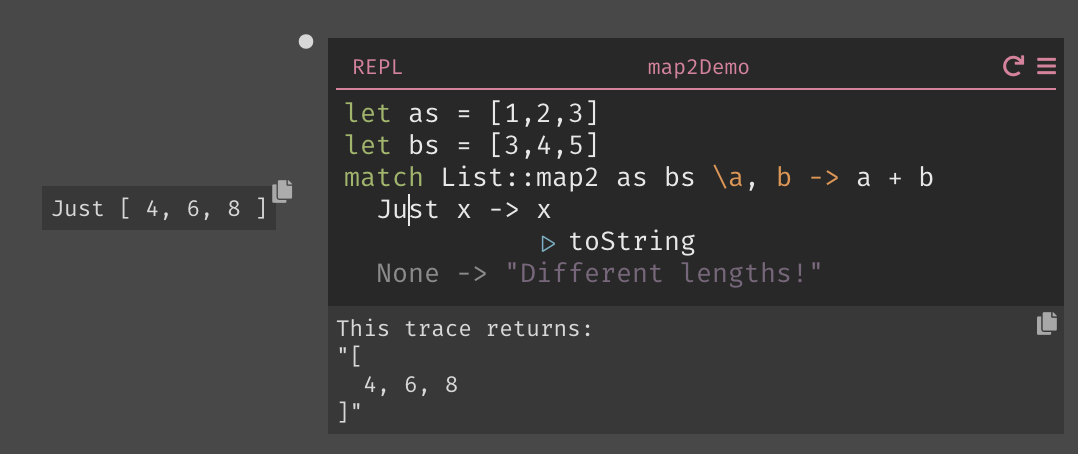
If the author knows the lists will never differ in length, they can stop there. Alternatively, they can take the function off the rail to handle the Option:
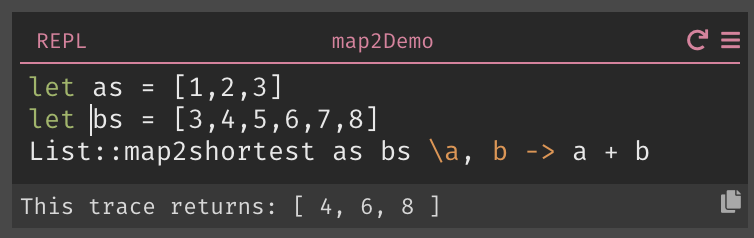
And if they want the behavior of dropping elements from the longer list, they can instead use our new List::map2shortest (when the coder goes to use map2, the autocomplete will present both options so this is discoverable):
NaNs and Infinity
There are similar problems around floating point. A goal in Dark is to not have NaN (NaN is the "not a number" floating point value that shows up when you perform floating point math with indeterminate results, like 0.0/0.0). Since Dark has structured error handling with a Result type, why should it also support implicit errors via NaNs?
Elm does have NaNs though, and so when we designed our floating-point functions, they had both different behavior in the case of NaNs, they also had different signatures (returning Results instead of plain Floats).
So we chose safety, and allowed the Error Rail to provide ease-of-use, right? Alas not. Unfortunately, we discovered that we don’t support the error rail for operators yet, which makes it hard to use Results for arithmetic. In addition, the error rail in its current manifestation is really about making prototyping easy, but you can't actually handle errors without taking values off the rail. This makes using it for something like arithmetic cumbersome. Alas, we had to shelve this for now.
Continuous Language delivery
We don’t believe we got everything right in this round of the standard library. Fortunately, we designed Dark to be easy to change, and each of the functions we added are individually versioned. This allows us to create new versions of the functions later, which developers using Dark can individually choose to upgrade.
Results
Over the course of the project we added 61 functions, in some cases deprecating old, poorly-named functions. In total, we now have 125 “basic” functions in the modules Bool, Float,Int, Math, Dict, List, Option, Result, and String (this does not include HTTP, DB, and other Dark "framework" modules).
Of these 125 functions, we ended up using different function names from Elm in 44 cases, different parameter order in 30 cases, and different behavior in at least 10 cases.
Elm has a great standard library, and it was a good starting point for expanding Dark. The subtleties of the language semantics and goals has a big impact on the standard library, and we discovered we needed to have good understanding of the differences between Elm and Dark as a result.
Learn More
- Come chat with Paul Biggar, our CTO, at an AMA on Friday, May 8th.
- Give Dark a try to see our standard library in action. (limited spots available)
- Once you have your Dark account, check out our standard library samples.