
Real problems with functional languages

And their influence on Dark
After two decades of coding professionally in a dozen languages, I’ve come to a conclusion about static and dynamic types:
- Static types help you ensure that your changes work, especially for changes that span large parts of the program. This leads to long-term productivity gains from reduction in errors, as well as code that works better.
- The lack of static types in dynamic languages allows you to prototype quicker and iterate faster. It also makes your code more readable.
The result is a productivity quagmire. Static languages bring the cost of type-safety to every line of code that is written, slowing development of new features and concepts. Dynamic languages’ lack of type safety produces significant costs down the line, eating the productivity benefit of the early quick prototyping.
In Dark, we want the advantages of both. We want to take a type-safe core with long-term productivity gains and risk-reduction, and use tooling to enable the quick prototyping and readable code that you get from dynamic languages.
What’s special about Dark?
Dark has a number of features that are different from regular programming languages. A quick intro:
- Dark’s goal is to remove accidental complexity from coding. We want you to write backend services quickly and safely, with little to no overhead.
- Dark is for building backends — you typically write HTTP handlers and we handle the deployment and infrastructure.
- Dark combines an editor, language and infrastructure, and we use the tight integration to overcome common limitations in programming languages.
- Dark doesn’t have a compilation step or separate compiler/interpreter. Instead, the editor updates with errors and warnings as you type (it also prevents syntax errors and some type errors).
- Dark is designed for continuous delivery — the practice of frequently making small, low-risk changes. Code that you write is deployed to “production” (typically behind a feature flag) immediately after being written.
Statically-typed Functional Languages
Statically-typed functional languages (hereafter FPs, with apologies to Lispers) are amazing. They have a property that exists almost nowhere else: once it compiles, it usually works first try. We obviously want this property in Dark, so we made Dark a statically-typed functional language.
(If you’re already very familiar with statically-typed functional languages, you can skip this section without missing much.)
Type safety
In FPs, the compiler checks if all the types line up, and if you’ve handled every possible edge case about your type. When you make a change, the compiler tells you every single place you need to change, which you need to figure out for yourself in dynamic languages. Importantly, that safety comes for free — you don’t have to write millions of unit tests to get it. The result is that small changes across large scale systems are pretty risk free. You can still get the logic wrong, but the plumbing is guaranteed to behave as expected.
Nulls
In almost every non-FP language, including Java, C, C++, Go, Python, Ruby, PHP, Erlang, Javascript, Clojure, Scala, SQL, C#, and Objective-C, any value can be null, and it can be extremely challenging to reason about whether a particular variable is or isn’t null in practice. Nulls cause program crashes when functions and methods are called on them, when they are indexed, and when their fields are accessed.
function leadPlayer(players) {
if (players.length <= 0)
return null;
return players[0];
}
function chooseCaptain(players) {
// throw a NullPointerException if the `players` list is empty.
leadPlayer(players).setCaptain(true);
}In the Java/Javascript-ish code above, the type system doesn’t protect against the NullPointerException when we expected an object but get a null.
FPs replace nulls with an Option type (called Maybe in Elm and Haskell, Option in Rust, Scala, and OCaml/F#, and Optional in Swift). The Option type encodes in the type system that a value can be null. If the value is not an Option, then it cannot be null.
Every time you have an Option, the compiler requires you to handle both potential cases: if it is a real value, or if it’s not. Since the compiler won’t let you access a field or index or call a method on a null value, that entire class of errors is removed.
function leadPlayer(players) {
match players with
| [] ->
return Nothing
| head :: rest -> // an array with 1 or more elements
return (Just head)
}
function chooseCaptain(players) {
match leadPlayer(players) with
| Just player ->
player.setCaptain(true); // we know this can't be null
| Nothing ->
// don't throw an exception
}As we can see, the FP version of the same code requires the null (called Nothing in our examples) to be handled.
Exceptions
Similarly, in most languages, any operation can cause an exception. Even Java with its checked exceptions has a category of exceptions (RuntimeExceptions) that can happen anywhere, including the beloved NullPointerException. Exceptions are so pervasive that it’s basically impossible to have a single line of code that is known to be exception-free — and even if it is, you won’t have a compiler to tell you that.
Here’s an example of some simple Python code that will throw an exception if aor bare strings which are not valid ints:
sum = int(a) + int(b);FPs commonly use a Result type instead of exceptions (or C/Go error codes). A Result is a value which is either a valid value or an error. Like the Option type, the compiler sees every Result and requires you to handle the potential error, knowing that you cannot do your regular type operations on an error.
Here’s the same in an Elm-like language with result types. As you can see, this requires you to handle both the errors of aand b.
match String.toInt a, String.toInt b with
| Ok a, Ok b ->
sum = a + b
| _ ->
Debug.log(“Error parsing integers);
sum = 0By removing both nulls and exceptions, FPs remove a huge set of possible errors, and allow developers the safety of knowing that their programs work. Most importantly, that knowledge comes from automatic tooling, not manually writing test cases.
Implementation in Dark
Dark takes influence from FPs, and Dark programs are fully type-checked. Dark’s type system allows us to find everywhere that a change needs to propagate, and tells you whether your types line up or not.
We also use Results and Options instead of exceptions and nulls, to avoid all the problems that come from those language features.
Downsides of Statically Typed Functional Languages
Unfortunately, these benefits come with significant frustrations and downsides, which current functional languages have — in our opinion — poor solutions for.
Type checking in Dark
In most FP compilers, your whole program either compiles or it doesn’t, making it difficult to make small scale changes. If I’m programming in Python, and I want to test out a quick hacky change in some component, I can do that immediately to discover whether the hack will even solve my problem.
Not so in FP. If I change a type in a FP, it might take me an hour to change every use of that type so that my program can even compile. And that’s assuming I’m stubbing out any logic that I don’t want to handle just yet. There’s little I find more frustrating than discovering in step 2 that the type changes I diligently propagated in step 1 were wrong and that I wasted the last hour.
Dark is designed for continuous delivery. As such, we don’t like requiring you to make large scale changes across your program, like changing a type everywhere. Instead, we want you to quickly discover that bad ideas won’t work, without first requiring you to propagate the type changes throughout your program.
Dark has a deliberately small compilation unit (the amount of code which is compiled together, and therefore which must be type checked together). You can make changes in a single HTTP route without having to make it type check with the rest of your program. This lowers the amount of type changes that you need to make to test out a single change.
The way this works is that you don’t actually change types in Dark. Instead, you make a copy of the type, and make your changes on that new copy. This allows you to prototype with the new type and test your change easily, making cheap iterations (and new types) as you try out new ideas. Once you are confident in your new type, you replace the uses of the old type (with semi-automated tooling to handle all the changes, including changes that are way down the call-stack).
As a result, you get the benefits of type checking, along with the benefits of cheap prototyping and quick iteration.
Option/Result types in Dark
If I want to use a value wrapped in an Option or Result, I must first unwrap it, and then handle the failure case. This ensures that my code handles all errors and edge cases, but also adds costs to prototyping and iteration. If I want to make a quick hack in Python or Javascript, I can ignore nulls and errors on the first pass as I prototype and develop my algorithm. Not so with static types — in fact, often I’m forced to do low-level restructuring of my code to handle Options and Results.
Consider the code I have to add to my prototype in our Elm-like example:
match String.toInt a, String.toInt b with
| Ok a, Ok b ->
sum = a + b
| _ ->
Debug.log(“Error parsing integers);
sum = 0The Python code was significantly faster to write (though it has bugs that we want to ignore during our prototype).
Dark uses a concept from Scott Wlaschin called “Railway Oriented Programming” to reduce this complexity. ROP is a metaphor where the error values of Results and Options form an alternate execution path through the program, called an Error Rail. When an error happens, the execution in the main body stops and instead passes over to the Error Rail.
Dark takes the ROP metaphor and makes a literal version of it in our editor. If you call a function in Dark that returns a Nothing(the name of the null-ish value of our Option type), the code execution jumps out of the body and down the Error Rail, which propagates the Nothing to the end of the function or HTTP handler. We do the same for Errors.
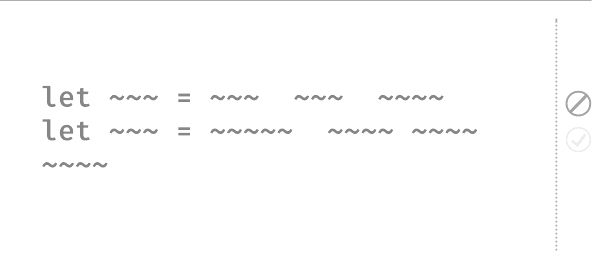
This is an early sketch of the the Error Rail (we aren’t showing actual screenshots until we launch). In the sketch, the highlighted ∅ icon indicates that that line of code had a function call that returned Nothing in the current execution trace. As a result, the execution jumped to the Error Rail, and the rest of the function did not execute. The ✔ icon on the following line indicates that if it had been executed, execution might jump to the Error Rail if its result was an Error.
It’s conceptually similar to Rust’s try! and ? macros, except that the Error Rail is automatic, and both the Error Rail as well as expressions that use it, are explicitly indicated in the editor.
This is the same code written with an error rail:
sum = String.toInt a + String.toInt bAs you can see, it’s exactly the same (aka just as simple) as coding in Python, but it brings with it the knowledge that you have type unsafe code to fix later.
After you’ve prototyped and validated your idea, then you will want to handle errors. Dark displays every point in your code which could contain an error. You can choose to handle those cases inline instead, or just leave them there until handling error cases becomes important to you. Or, in the common case where the feature is scrapped and the code is thrown away, you’ll never have paid the type tax for that code.
We also anticipate adding ways to handle errors directly on the rail in the future, with default values, notifications about run-time errors, etc.
The FP rabbit hole
One of the temptations of FPs is to solve all problems with more types. Options and Results have problems, so we invent monads, combinators, or other type trickery to deal with them.
A core thesis of Dark is “Don’t use the word ‘monads’”. We believe that while there are significant advantages to FPs, it is very easy to cross the line into a place where the type system increases complexity.
As a result, we call Dark a “functional/imperative hybrid”, and model it after OCaml/ReasonML and Elm and Rust, rather than Haskell or Scala. We want our language to be easy to understand and learn for programmers who know imperative or OO-languages, and we especially don’t want anyone to need to even be aware of category theory.
As such, we’ve skipped monads, combinators (really any obscure infix function names), lenses, and plenty more. Instead, we’ll replace them with editor tooling that we hope will have the same upside.
Have your cake and eat it
Dark is designed for productivity. We want to remove all the accidental complexity from coding. Along with their ease of prototyping, dynamic languages bring the accidental complexity of run-time errors. Along with their large-scale automatic type safety, static languages impose a cost on every line of code written, regardless of whether that code is ever actually used.
Dark’s tight integration of editor tooling and programming language allows us do things like the Error Rail, versioned types and functions, and small compilation units, that are a challenge to achieve with the loose programming language/editor coupling that is common today. We believe this will allow us to get the best of coding in both statically and dynamically typed languages.
To read more about the design of Dark, check out What is Dark, follow us on Twitter (or just me), or join our beta.
Thanks to Aidan Cunniffe, Arty Vohmincevs, Dan Bentley, Daniel Mangum, Dhash Shrivathsa, Jared Forsyth, J David Eisenberg, Karthik Venkat, Peteris Erins, and Sean Grove for reviewing drafts of this post.