
How Dark deploys code in 50ms

Speed of developer iteration is the single most important factor in how quickly a technology company can move.
Unfortunately, modern applications work against us: our systems are required to be live updated, silently and without downtime or maintenance windows. Deploying into these live systems is tough, requiring complex Continuous Delivery pipelines, even for small teams.
These pipelines are typically ad-hoc, brittle, and slow. They need engineering time to build and manage, and companies often hire entire Devops teams to maintain them.
The speed of these pipelines dictate the speed of developer iteration. The best teams manage deploy times around 5–10 minutes, but most take considerably longer, in many cases hours for a single deploy.
In Dark, deploys take 50ms. Fifty! Milliseconds! Dark is a holistic programming language, editor and infrastructure that’s designed from the ground up for Continuous Delivery, and every aspect of Dark, including the language itself, was built around safe, instant deploys.
Why are Continuous Delivery pipelines so long?
Let’s suppose we have a Python web application, and that we have already built an amazing modern continuous delivery pipeline. For a developer who is working on this project day-to-day, deploying a single, small change probably resembles the following:
Make the changes
- Create a new branch in git
- Make the changes behind a feature flag
- Run unit tests to validate your changes with the feature flag both on and off
Pull request
- Commit the changes
- Push the changes to a remote on github
- Make a pull request
- CI build runs automatically in the background
- Code review
- Repeat this step a few times perhaps
- Merge the changes into git main branch
CI runs on main branch
- Install frontend dependencies via npm
- Build/optimize HTML+CSS+JS assets
- Run frontend unit/functional tests
- Install Python dependencies from PyPI
- Run backend unit/functional tests
- Run integration tests against both assets
- Push frontend assets to a CDN
- Build a container for the Python program
- Push container to registry
- Update kubernetes manifest
Replace old code with new code
- Kubernetes spins up some instances of the new container
- Kubernetes waits for those instances to become healthy
- Kubernetes add those instances to the HTTP load balancer
- Kubernetes waits for old instances to become unused
- Kubernetes spins down old instances
- Kubernetes repeats until all old instances have been replaced with new ones
Enable new feature flag
- Enable the new code for just yourself, gain confidence
- Enable the new code for 10% of your users, watch operational and business metrics
- Enable the new code for 50% of your users, watch operational and business metrics
- Enable the new code for 100% of your users, watch operational and business metrics
- Finally, go through the entire process again to remove the old code and the feature flag
You’ll have a different setup depending on your tooling, language, and use of service-oriented architectures, but this feels representative. I’ve haven’t listed deploys with DB migrations since they typically require careful planning, but I discuss Dark’s solution to that below.
There are many moving parts here, and most of them either take a long time to run, can fail, introduce temporary race conditions, or may crash the running production system.
Since these pipelines are almost always ad-hoc, they are often brittle. Most of us will have had to deal with days when it’s not possible to deploy code because of some problem in a Dockerfile, one of the dozen services involved is having an outage, or the exact person who’s needed to understand a build failure is on vacation.
Worse, many of these steps provide no value. It used to be that deploying code enabled it for users, but we have separated those steps, and now code is enabled with feature flags. As a result, the code deploy step — replacing the old code with the new code — now just introduces risk.
Of course, this is an extremely advanced pipeline. The team that built this invested significant engineering time and money in this pipeline to get fast deploys. Most teams have significantly slower and more brittle deployment pipelines.
Dark’s Continuous Delivery design
Continuous Delivery is so integral to Dark that we designed it from the start to have sub-second deploy times. We looked at the pipeline to remove every step possible from it, and made the rest of the steps world class. Here’s how we removed all the steps.
#deployless
https://t.co/rFdPgX4WzF looks super cool, the short demo from @paulbiggar is impressive.... I can't resist the urge to call it "deployless"
— Jessie Frazelle (@jessfraz) June 28, 2018
The first and most important decision was to make Dark “deployless” (thanks to Jessie Frazelle for coining the term). Deployless means that anything you type is instantly deployed and immediately usable in production. That doesn’t mean we let you ship broken or incomplete code though (we discuss our designs for safety below).
When demoing Dark, we often get asked how we managed to make our deploys so fast, which always strikes me as an odd question. I suspect people think that we developed some incredibly advanced technology that can diff code, compile it, containerize it, spin up a VM, and cold-start the container, etc, etc, in 50ms, which is probably impossible. Rather, we built a customized deployment engine which doesn’t need to do any of those.
Dark runs interpreters in the cloud. When you write new code in a function or HTTP/event handler, we send a diff of the Abstract Syntax Tree (the representation of your code that our editor and servers use under the hood) to our servers, and then we run that code when requests come in. So deployment is just a small write to a database, which is instant and atomic. Our deploys are so fast because we trimmed a deploy to the smallest thing possible.
In the future, Dark aims to be an infrastructure compiler, creating and running the ideal infrastructure for the performance and reliability of your app. We will keep the instant nature of deployment when we move in that direction later.
Making deployment safe
Structured Editor
Code in Dark is written in the Dark editor. The structured editor doesn’t allow you to make syntax errors. In fact, Dark doesn’t even have a parser. As you type, we manipulate the AST directly, similar to Paredit, Sketch-n-Sketch, Tofu, Prune, Lamdu, and MPS.
Every state of incomplete code in Dark has a valid execution semantics, similar to typed holes in Hazel. For example, as you change a function call, we maintain the memory of the old function until the new one is valid.
Since every program in Dark has meaning, incomplete code doesn’t prevent complete code from working.
Editing modes
There are two situations where you’re writing code in Dark. In the first, you’re writing new code and you’re the only user. Perhaps it’s in the REPL so no users will ever touch it, or it’s a new HTTP route that you don’t link to from anywhere. This is safe to edit without any guard rails, and most closely resembles coding in your dev environment today.
The second is code that is currently in use. Any code that has traffic flowing through it, whether functions, event handlers, databases, or types, needs to be safely editable. We handle this by “locking” all code that’s in use, and requiring you to use more structured tooling to edit it. The structural tooling is discussed below: feature flags for HTTP/event handlers, a powerful migration framework for DBs, and a novel versioning technique for functions and types.
Feature flags
One way to reduce accidental complexity in Dark is by solving many different problems with a single solution. Feature flags is our workhorse: replacing local dev environments, git branches, code deployment, and of course still providing the traditional use-case of slow, controlled roll-out of new code.
Creating and deploying a feature flag is a single operation in our editor. It creates a blank space to add new code, and provides the knobs to control who sees the old and new code, as well as a button/command to atomically switch over to the new code or abandon it.
Feature flags are built into the Dark language, and even incomplete flags have meaning; a flag where the condition hasn’t been filled in will execute the old locked code.
Dev environment
Feature flags replace having a local dev environment. Today, teams struggle to keep everyone using the same versions of tools and libraries, whether code formatters, linters, package managers, compilers and preprocessors, test tools, etc. With Dark, there’s no need to install dependencies locally, manage a local docker setup, or any of the steps involved in maintaining some semblance of dev/production parity. Given that dev/production parity isn’t really possible anyway, we’re better off not pretending we can actually do this.
Instead of trying to create a cloned local environment, feature flags in Dark create a new sandbox in production, which replaces the dev environment. In the future we also plan to sandbox other parts of your app — instant database clones for example — though we haven’t found these to be as important so far.
Branches and deploys
There are several different ways of introducing new code into a system today: git branches, a deployment step, and feature flags. They solve the same problem in different parts of the workflow: git in the pre-deployment stages; the deployment step at the moment of transitioning from the old code bundle to the new one; and feature flags for controlled rollout of new code.
Feature flags are the most powerful of these (and arguably the simplest to understand and use), and enables us to entirely remove both other concepts. The deployment concept is particularly useful to remove: if feature flags are what we use to enable code anyway, then the “switch our servers to new code” step only introduces risk to your deployment.
While git is hard to use and beginner unfriendly — a true gatekeeping technology — branches are nice concept. Many of the downsides of git are reduced; Dark is live edited and uses Google-Docs-style real-time collaboration, removing the concept of pushes and reducing the need for rebases and merges.
Feature flags are the cornerstone of our safe deploys. By combining them with instant deploys, developers can quickly test concepts in small, low-risk chunks, never having a single large change that can take down a system.
Versioning
To make changes to functions and types, we use versioning. If you want to edit a function, Dark creates a new version of that function, and allows you to call that version from a feature flag in the HTTP/event handler. (If that function is deep in the callgraph, this makes a new version of every function along the way; this seems like a lot, but functions stay out of your way unless you use them, so you won’t notice).
We also version types, for similar reasons. We discussed our type system more in our last post.
By versioning functions and types, we allow you to slowly make changes to your app. You can validate that each handler continues to work with the new version individually, and you don’t need to make wholesale changes to your app (we provide tooling to allow you make them very quickly, if you prefer).
This is much safer than the all-or-nothing deploys that happen today.
New versions of packages and standard library
When you upgrade a package in Dark, we don’t just replace the use of every function or type across your codebase immediately — that doesn’t seem safe. Rather, all code continues using the exact same version that they were using, and you gain the option of upgrading uses of functions and types to the new version on a case-by-case basis using feature flags.

We frequently provide new standard library functions, and deprecate old versions. Users who are using specific old versions in their code continue to have access to them, while we hide old deprecated versions for users who do not. We expect to provide tooling to upgrade users from old versions to new versions in one step, again using feature flags.
Dark also has a unique ability: because we run your production code, we can test the new versions for you, comparing their output for both new requests and past requests, to tell you if anything changed. This turns package updates that are largely blind (or rely on extensive testing for safety) into something with significantly lower risk, which may be upgradable automatically.
New versions of Dark
The Python 2 to Python 3 conversion has been going for a decade and remains a problem today. Given that we’re designing Dark for continuous delivery, we need to account for language changes too.
In Dark, when we make small language changes, we create a new version of Dark. Old code stays on the old version of Dark, and new code starts using the new version. You can use feature flags or function versions to switch over to the new Dark version.
This is especially useful since Dark is so young. There are many changes to the language and library that may or may not be good ideas. Versioning the language in small increments allows us to make small updates, meaning we can delay many language decisions until we have more users, and hence more information, rather than solving them all now.
DB migrations
To do DB data migrations safely today, there is a standard formula:
- rewrite your code to support both the new format and the old one
- convert all your data to the new format
- remove the old way of accessing the data
This process turns DB migrations into long-running, expensive projects. The result is that many of us have outdated schemas, as fixing even simple things like table and column names isn’t worth the cost.
Dark has a powerful DB migration framework that we believe makes DB migrations so simple you will do them often. All datastores in Dark (which are key-value stores / persistant hashtables) have a type. To migrate a datastore, you just give it a new type, and a rollback and rollforward function to convert values back and forth between the two types.
Datastores in Dark are accessed via versioned variable names. For example, a Users datastore will initially be accessed as Users-v0. When a new version, with a different type, is created, it is accessible as Users-v1. Data saved via Users-v0 that is accessed via Users-v1 has the roll-forward function applied to it. Data saved via Users-v1 that is accessed via Users-v0 has the rollback function applied to it.
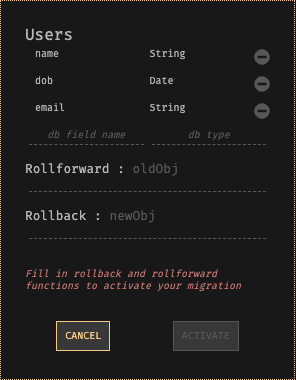
You use feature flags to switch DB calls to Users-v0 over to Users-v1. You can do this a single HTTP handler at a time to reduce the risk, and feature flags allow you to enable them for single users to ensure they work as planned. Once there are no uses of Users-v0 anymore, Dark will convert all remaining data in the background, from the old format to the new format. This should be invisible to you.
Testing
Dark is a statically-typed functional language, with immutable values. This significantly reduces the testing surface compared to dynamically-typed, object-oriented languages, but we still need testing.
In Dark, the editor automatically runs unit tests in the background for code that’s being edited, and runs those tests across all feature flags by default. We also expect to use our static types to automatically fuzz your code, finding bugs for you.
Dark also runs your infrastructure in production, and this allows new abilities. We automatically save HTTP requests to Dark infrastructure (currently we save them all but we’ll move to sampling in the future). We test new code against those as well as unit tests, and make it easy to convert interesting requests to unit tests.
What have we removed?
The combination of deployless and feature flags means that about 60% of the deployment pipeline is no longer necessary. We do not need git branches or pull requests, building backend assets and containers, pushing those assets and containers to registries, or any part of the Kubernetes deployment steps.
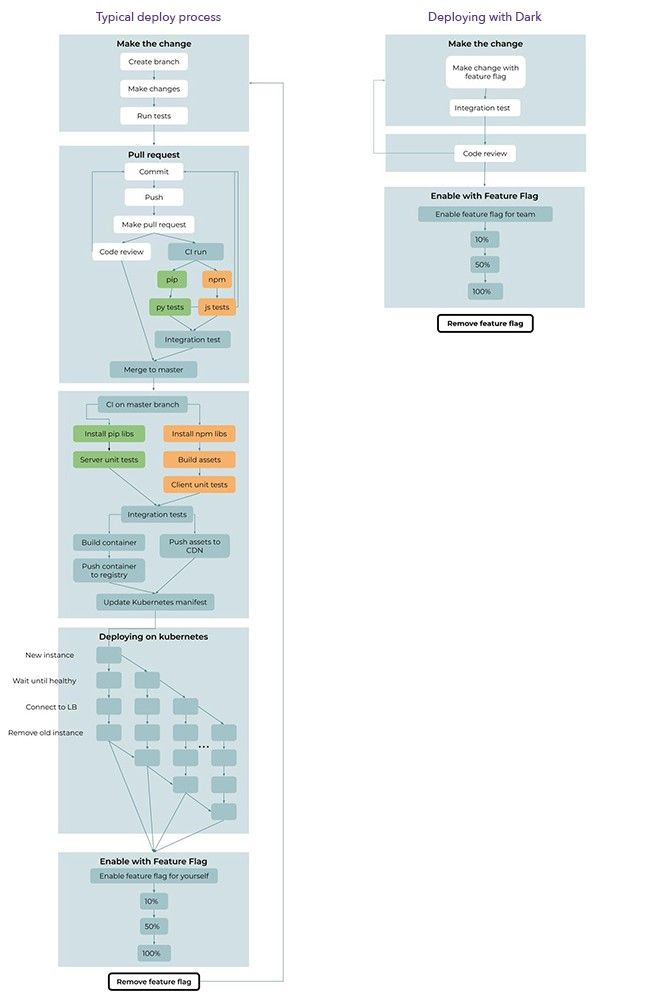
A deployment in Dark has only 6 steps and one loop (steps that are repeated multiple times), while the modern Continuous Delivery pipeline has 35 steps and three loops. In Dark, tests run automatically behind the scenes; dependencies install automatically; anything involving git or Github is no longer necessary; building, testing and pushing Docker containers are not necessary; and no Kubernetes deploy steps are needed.
Even the steps which remain are simpler in Dark. Since feature flags can be completed or dismissed in a single atomic action, there is no need to go through the entire deploy pipeline a second time to remove the old code.
This is as close to the essential complexity of shipping code as we can imagine, significantly reducing both the time and the risk of continuous delivery. We’ve also significantly simplified upgrading packages, DB migrations, testing, version control, installing dependencies, dev/production parity, and upgrading quickly and safely between language versions.
I’m answering questions about this on HackerNews.
To read more about the design of Dark, check out What is Dark, follow us on Twitter (or just me), or join our beta.
Thanks to Ben Beattie-Hood, Charity Majors, Chris Biscardi, Craig Kerstiens, Daniel Mangum, Domantas Mauruča, Eric Ries, Jennifer Wei, John Obelenus, Jorge Ortiz, K. Rainbolt-Greene, Kent Beck, Matthew Wilson, and Russell Smith for reading drafts of this post.