
Compiling Dark to SQL

How do we make programs in Dark fast, while keeping complexity for developers really low?
We recently shipped a new Dark feature that compiles Dark code to SQL. This post goes into the nitty gritty details of how and why we built it.
First, let’s see it in action:
Complexity
One of the premises of Dark is that it breaks down the wall between the datastore and the language. We want to significantly reduce complexity, and one source of that complexity is that databases (whether SQL or NoSQL) have different semantics from our code. This means to use them, you need to understand the code and the DB really well, but you also need to understand the mapping (often an ORM like ActiveRecord) really well.
Instead, we want datastores with the same semantics as our language: the same types and the same code to query and update them. At the same time, developers expect the same sort of performance in Dark that they’re able to get from writing SQL and managing a database themselves. How can we get the best of both worlds?
Initial design
Last year, the way to access stored data in Dark was like this:
DB::getAll People
|> List::filter (\\p -> p.age >= 18 && p.state != "CA")
|> List::sortBy (\\p -> p.name)This would get everyone in the database into a list, run through the list to only keep people over 18 outside California, then sort them by name. This means that you’re writing all your code in Dark, but the downside is that you have to load the entire table and run through every single entry in memory. In addition to the really poor performance, as well as scalability limits, it broke our editor: we show you a “live value” of every computation in Dark (you can see them in the gif above), but our editor cannot display more than about 40KB per entry.
We added a stopgap, like this:
DB::query People
{
age : 18,
state : "CA"
}But this only worked for exactly matching fields, and didn’t work for inequalities and comparisons. We briefly thought about adding operators like in MongoDB like this:
DB::query People
{
age : { $ge: 18 }
state : { $ne: "CA" }
}but the less said about this the better.
By contrast, if I was using PostgresQL, I would write:
SELECT * FROM People WHERE age >= 18 AND state <> 'CA'
The advantage here is that it would be really fast, but there are a bunch of downsides that come from using a different language/tooling/technology to do this.
We wanted the best of both worlds: have great performance while also having the low cognitive overhead of just using the same language and types for everything. So why not just compile the original code to an optimized query?
Startups
Unfortunately, we have some real constraints at Dark. We’re building a programming language, an editor, and infrastructure. Of course we get some wonderful economies of scale from only having to make them work with each other, but we still need to be very careful about the scope of what we build. Essentially, we wanted to automatically gain this performance, but we also wanted to make sure we didn’t bite off a project larger than about 1 person week.
Constraints of the initial design
There were a couple of problems with compiling this code directly:
DB::getAll People
|> List::filter (\\p -> p.age >= 18 && p.state != "CA")
|> List::sortBy (\\p -> p.name)- We don’t have a framework to do a compilation step in Dark yet. So to do analysis of a whole function to determine if we can optimize it would take longer than the timeframe for this project.
- We show livevalues for every computation in Dark, and didn’t know what to do if we optimized out some of the steps. We could probably have designed and implemented this in the timeframe allowed, but we didn’t want to do both that and the optimization.
What we needed was a design for a feature that barely changed the product except for the optimization.
Revised design
At some point, someone (apologies, I don’t remember who) either suggested or made me think of this alternative design:
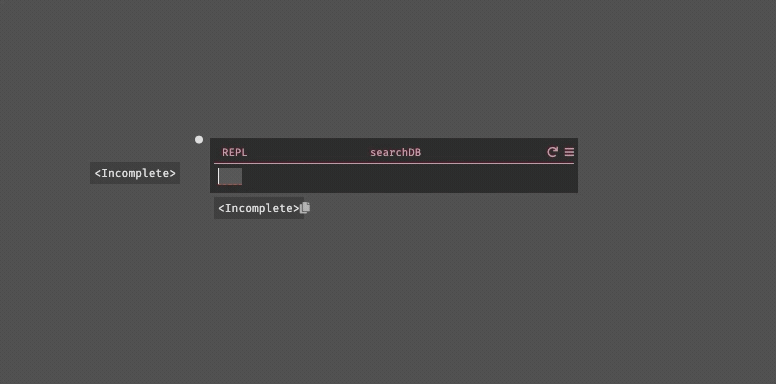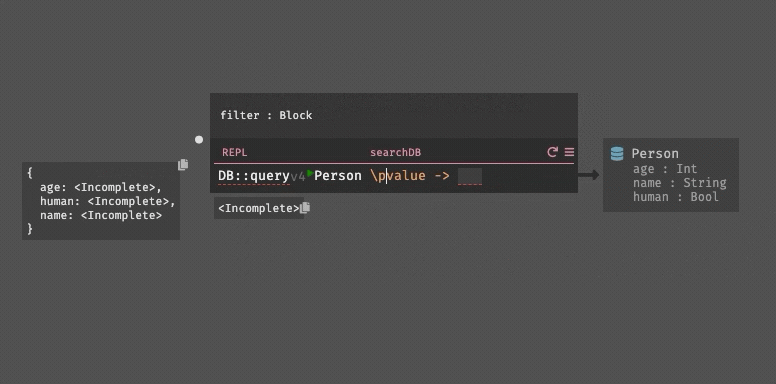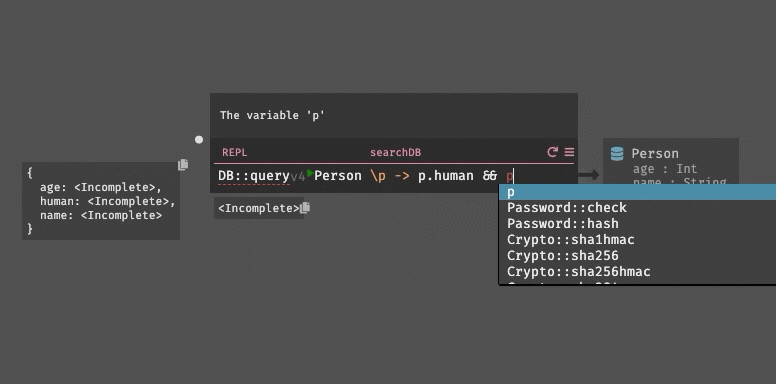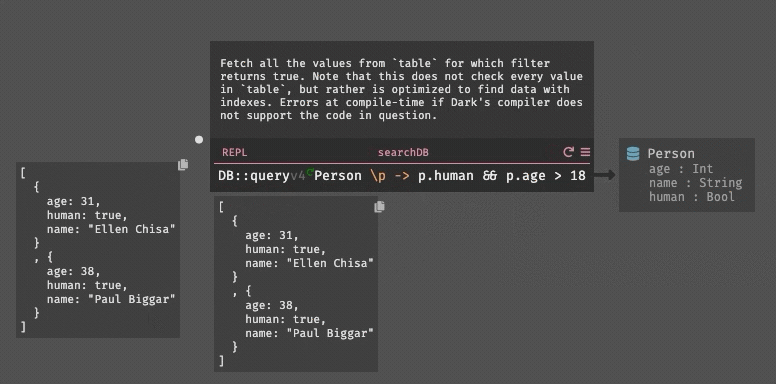
DB::query People (\\p -> p.age >= 18 && p.state != "CA")
|> List::sortBy (\\p -> p.name)The difference here is not particularly large, but it allows us solve the previous problems:
- this limits the amount of code we have to compile to just code within a lambda that’s an argument of
DB::query; this means it's short enough to do as the query is executed, without an extra compilation step - the livevalue for
DB::queryincludes only the results we care about, not every value in the datastore - there are no intermediate stages with missing livevalues, so we don’t need any new UX
This meant that we could design the optimizer without introducing larger product or infrastructure concerns. When we learned more about how people used it, we could build subsequent features, and perhaps eventually end up at the original design, or learn that we want to go in a different direction.
In most languages, adding functions to the standard library cannot be done lightly, as these functions will stay for all time. However, Dark is designed to deal with this issue. All functions are versioned and can be deprecated — deprecated functions/versions do not appear to you unless you already use them. In addition, we are able to automatically transform programs using old versions of functions to new versions if we know that this is safe. As such, trying out small experiments like this is low risk.
Meaty technical details start here
So now that we know what we want to compile, how do we actually compile this?
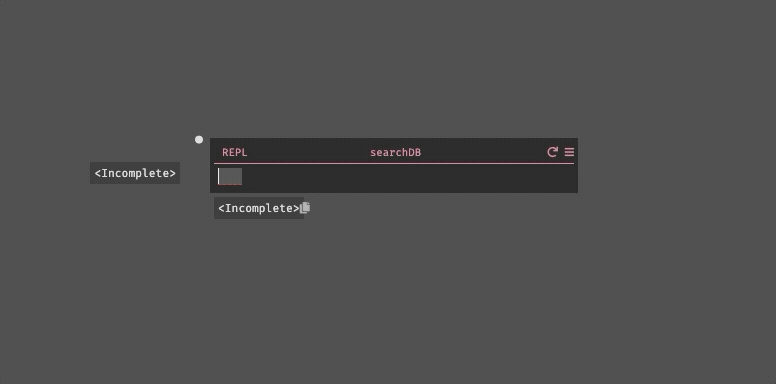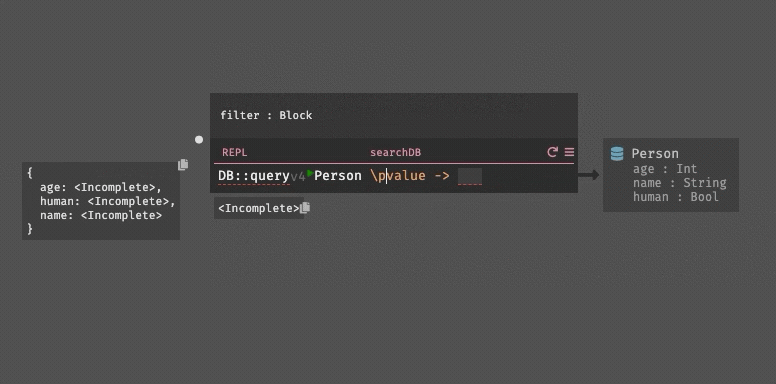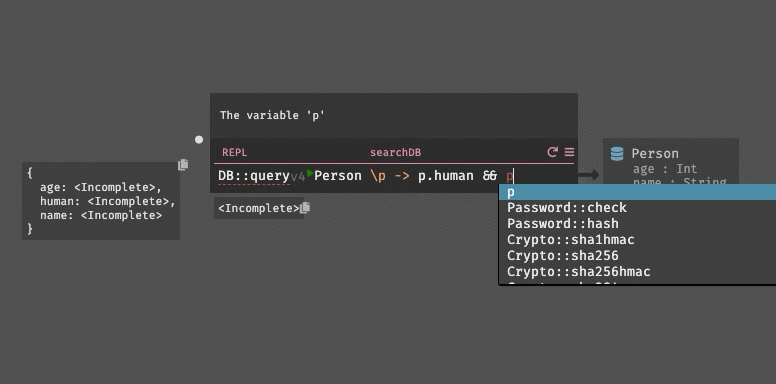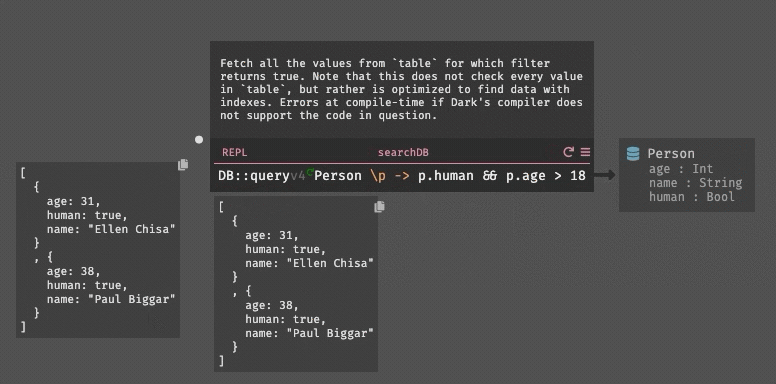
DB::query People (\\p -> p.age >= 18 && p.state != "CA")
Dark’s datastores
Dark’s current datastore is a giant database on Google’s Cloud SQL, running PostgreSQL. The table uses jsonb, and everything stored in the database is serialized to JSON before being added. This was originally designed for time to market, maintainability, as well as ability to scale in the future — it is straightforward to shard or move customers to other machines, and we get to learn about real data patterns of our customers before designing the next level of scalability.
Code in Dark
All code in Dark is represented using an “abstract syntax tree” which is a terribly complex name for a very simple concept. It means that rather than keeping code in simple text, we have a set of types that represent language constructs, such as strings, functions, variables, integers, etc. Roughly speaking:
type expr =
| Integer of string
| String of string
| If of expr * expr * expr
| Variable of string
| FnCall of string * expr list
| Lambda of string list * expr(If you’re not familiar with types like this, you can think of this as a bunch of subclasses of the expr class.)
Compilers
Compilers are much simpler concepts than people think. The idea is you take an AST (or “set of types representing a program”) and go through them turning them into strings. In our case, we want to turn
-- \\p -> p.age >= 18 && p.state != "CA"
(Lambda ["p"]
(FnCall "&&" [
(FnCall ">=" [FieldAccess (Variable "p") "age"]),
(FnCall "!=" [FieldAccess (Variable "p") "state"])
]))into
# \\p -> p.age >= 18 && p.state != "CA"
age >= 18 AND state <> 'CA'I’m going to jump straight to the solution, with the hard bits hidden (and the syntax made a bit more readable for non-OCaml folk), and then discuss the complexities later:
let expr_to_sql expr =
match expr with
| Int int ->
"(" ++ Int.to_string int ++ ")"
| String str ->
"('" ++ escape_string str ++ "')"
| FieldAccess (Variable "value") fieldname) ->
fieldname
| FnCall (op, [e]) ->
"(" ++ op_to_sql op ++ " " ++ expr_to_sql e ++ ")"
| FnCall (op, [l, r]) ->
"(" ++ expr_to_sql l ++ " " ++ op_to_sql op ++ " " ++ expr_to_sql r ++ ")"So what we see here:
- Function calls, like
+,==, etc, are looked up in a table (op_to_sql) for their corresponding SQL equivalent - Integers and strings are escaped and wrapped in parentheses
- Field accesses like
p.ageare turned into that variable name (eg justage)
So the SQL output is just:
((age) >= (18)) AND ((state) <> ('CA'))
The harder bits
That was a version that was as cut down as possible. We also added support for many more features in order to be useful. These are the ones with the least technically interesting implementation:
- support any parameter name you want, not just
value - the SQL syntax for
nullismyVar is nullnot=, so that needed to be special cased - Every expression was a possible vector for SQL injection, so apart from many rounds of code review, we also had to add escaping in a lot of places, and add tests for each one of them.
- we were using JSONB, so we actually needed to cast JSON to the correct type once it was fetched. We passed in the Datastore definition to get the types, and then here’s what the SQL looked like:
(CAST(data::jsonb->>'age' as numeric))
After that last change, the compiled SQL isn’t looking so pretty anymore:
((CAST(data::jsonb->>'age' as numeric)) >= (18))
AND ((CAST(data::jsonb->>'state' as text) <> ('CA'))Internal representation of Lambdas
To support compiling our AST in the first place, we first needed to make some internal changes to how lambda’s work in Dark. If you’re not familiar, a lambda is an anonymous function that you can create dynamically. It’s the same idea as Arrow Functions in Javascript:
-- in JS
let isChild = function (person) { return person.age < 18; }
let isChild = person => person.age < 18
-- In Dark
let isChild = \\person -> person.age < 18We previously showed you how we represent things at compile-time, now let’s look at the runtime. In Dark, all run-time values are called dvals. This is pretty similar to how other interpreters work: values in PHP are called zvals, in Python they're called PyObject and in Ruby they're called VALUE. A dval is a type that can be any value allowed in Dark:
type dval =
| DBlock of (dval list -> dval)
| DInt of int
| DList of dval array
| ...etcWhen a lambda executes, it created and returns a DBlock. The value of a DBlock is a function which is then called when you apply the DBlock. The function takes a list of dvals and returns another dval. So that mirrors the Lambda definition:
type expr =
| Lambda of string list * expr
| ...etcThe strings in a Lambda are the names of the parameters that correspond to the dval list in the DBlock.
A compiled OCaml function is not analyzable however, so before we did anything above, we had the change a DBlock to actually store the body of the Lambda, so that we could compile it into an SQL string. A DBlock’s new definition was:
type dval =
| DBlock of symtable * string list * expr
| ...etcA “symtable” is a symbol table, literally just the names of all the variables in scope and their values.
The new definition raised a couple of interesting questions for us. Now that we could store actual Dark code within a Dark value, could we also let users store code in a Datastore? Could they resurrect 3 year old code and expect it to execute? Could we return it over HTTP? Could we consume it over HTTP, parse it, and then execute it? All of these questions terrified us, and we decided to disallow all of these behaviors.
Now that we had the expression available within a DBlock, we had something to analyze and compile in DB::query, enabling all the compilation we've discussed above.
Supporting more Dark code — variables
The compiler we’ve discussed so far supports the simplest parts of Dark, but what about the more complex stuff? It’s pretty useful to use variables from outside the block in the query:
let age = request.body.age
DB::query Person (\\p -> p.age > age)Now that we have a symtable, let’s look at our compilation function again:
let expr_to_sql symtable expr =
match expr with
| Variable (name) ->
"(" ++ dval_to_sql (Symtable.get name) ++ ")"
| ...etc
Supporting more Dark code — inlining
That allowed us to support variables defined before the lambda, but what about variables inside the lambda?
DB::query Person
(\\p ->
let age = 36 / 2
p.age > age)
Some variants of SQL has a notion of variables, but they were hard for us to use, so compiling these directly into SQL didn’t make sense. Instead, we inlined all these expressions by preprocessing the AST, leaving us with
DB::query Person (\\p -> p.age > (36 / 2))Supporting more Dark code — Pipes
One of my favorite features in Dark is pipes, similar to Bash, Elixir, OCaml, Elm and Clojure (where they are called “threads”):
[1,2,3,4]
|> List::map (\\i -> i + 1)
|> List::sum
|> (/) 2
-- final result is 7The result of each previous expression is passed as an argument into the next function. Of course, SQL doesn’t support this. So to support this, we preprocess it, which we call “canonicalization”. Canonicalization means turning the program into a canonical form, meaning making sure there is only one way to represent a particular program. The program above would become:
(2 / List::sum (List::map (\\i -> i + 1) [1,2,3,4]))Type checker
So far we’ve gotten away without a type checker. We’ve compiled our Dark code directly to SQL, but what happens if the types are bad. SQL will raise an error!
Passing SQL errors directly to developers would be a pretty bad experience, and parsing PostgreSQLs errors would be challenging and error prone. We don’t want to tell users that there’s a type error but not telling them where. So we added a type checker.
A type checker is another thing that is only complicated in theory. Our implementation was very simple:
- for each expression, pass in the type we expect it to be. For example, the top level expression to
DB::queryshould be abool - for every expression, check its type against the expected type
Here’s what that does to the implementation:
let typecheck msg actual expected =
if expected != TAny && actual != expected
then error "Invalid type: " ++ (msg, actual, expected)
let expr_to_sql
(expected_tipe : tipe)
(expr : expr) : string =
match expr with
| Int int ->
typecheckDval int TInt expected_tipe ;
"(" ++ int ++ ")"
| String str ->
typecheckDval str TString expected_tipe ;
"('" ++ str ++ "')"
| FnCall (op, [e]) ->
let arg_tipe, result_tipe, opname = unary_op_to_sql op in
typecheck op result_tipe expected_tipe ;
"(" ++ opname ++ " " ++ expr_to_sql arg_tipe e ++ ")"
| FnCall (op, [l, r]) ->
let ltipe, rtipe, result_tipe, opname = binop_to_sql op in
typecheck op result_tipe expected_tipe ;
"(" ++ expr_to_sql ltipe l
++ " " ++ opname ++ " "
++ expr_to_sql rtipe r
++ ")"
| ...etc
Conclusion
After changing the implementation of Lambda, the Dark to SQL compiler ended up at 250 lines of code, most of which was the table converting Dark functions to their SQL equivalents, and a similar number of tests.
Dark is in private beta, sign up at https://darklang.com/beta. We have been letting people into the beta who want to build a Slack bot or React app. If you have an app like that to build, we will let you in shortly. If you don’t, sign up anyway and we’ll let you in as soon as possible.